Princeton Just Confirmed It. We Said It First.
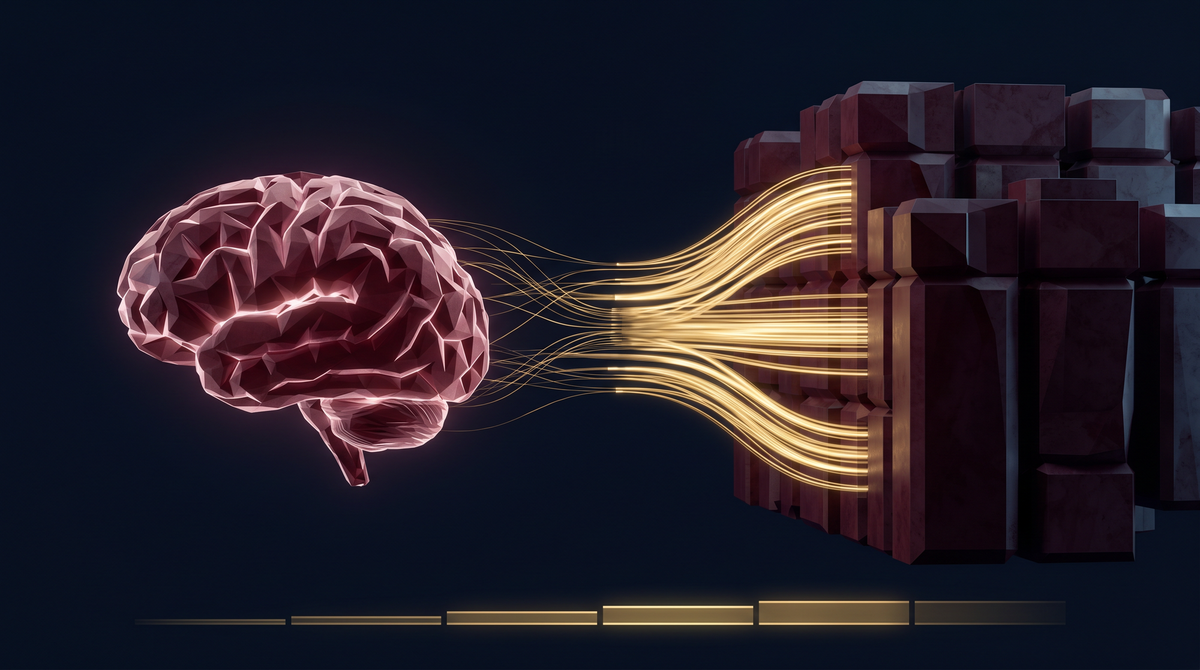
One millionth of the power. Not a rounding error. A thermodynamic indictment.
Princeton Just Confirmed It. We Said It First.
Three weeks ago, Deconstructing Babel published "It's Not Compute. It's Not Throughput. It's Something Else." The argument was simple, and the industry was not ready to hear it: the entire Ai scaling race is chasing the wrong variable. This week, researchers at Princeton University said it out loud from a neuroscience lab. The human brain runs on roughly 20 watts. The frontier Ai systems being scaled today require up to one million times that to perform comparable tasks. That is not a rounding error. That is a thermodynamic indictment of the entire current architecture — and it is the argument we made on April 5.
More GPUs. More data centers. More gigawatts. The assumption baked into every headline, every investor deck, every congressional hearing is that intelligence scales with silicon and the bottleneck is processing power.
The assumption is wrong.
This week, Dr. Yuxiu Fu, whose Princeton team was studying the brain's energy mechanics, put it plainly: "The real bottleneck for Ai in the near future is energy. Our brain consumes only a tiny fraction — about one millionth — of the power consumed by today's Ai systems to perform similar tasks."1
One millionth.
Not ten percent less. Not twice as efficient. One millionth of the power. That is not an incremental gap you close with better cooling systems or more efficient chips. That is a species-level architectural verdict.
What We Said on April 5
The human brain operates at approximately 20 watts — sustained, measured, and well-documented across four decades of neuroscience literature. A ChatGPT-scale Ai system consumes approximately 9 megawatts to serve inference load at comparable throughput. A gigawatt-class Ai data center draws 50 million times what a single brain requires. These are not implementation details. They are orders-of-magnitude misallocations of resources driven by a fundamental misunderstanding of what we actually have.
The 20-watt figure is not a marketing claim. It is published, measured, and replicated. The brain accounts for approximately 2% of adult body mass and consumes roughly 20% of total basal metabolic energy — about 20 watts continuously.2 That power draw is remarkably stable: brain energy consumption between "resting" and "busy" states is nearly identical, because when some regions work intensively, others quiet down. The brain runs at approximately maximum power constantly, whether you are solving a differential equation or staring at the wall.2
By comparison, the International Energy Agency and Brookings Institution now estimate that global data-center electricity consumption will approach 1,050 TWh by 2026 — which, if data centers were a country, would make them the fifth-largest energy consumer in the world, between Japan and Russia.3 Anthropic has publicly estimated that training a single frontier Ai model will require 5 gigawatts of power by 2027. The broader U.S. Ai sector will require approximately 50 gigawatts of new electric capacity by 2028 to maintain what the industry calls "global Ai leadership."3 Former Google CEO Eric Schmidt testified to Congress that data centers will need 29 additional gigawatts by 2027 and 67 more by 2030.3
Put those numbers next to 20 watts. That is the scale of the misallocation.
What we have is not artificial intelligence. What we have is a sophisticated retrieval system — and it is sitting next to the most energy-efficient computer in the known universe. The one between your ears.
The inversion is this: Ai retrieves. The brain computes.
When you pair a retrieval system with a biological compute system, you get a third thing — something neither could produce alone. That third thing does not require building another gigawatt data center. It requires keeping the biological compute layer healthy, connected, and resourced.
That is not a hardware problem. That is a human infrastructure problem.
Why Princeton's Timing Matters
The Princeton team was not studying Ai. They were studying fundamental neuroscience — how the brain manages energy at the synaptic level. They stumbled into an Ai implication and had the intellectual honesty to name it publicly. That is how real paradigm shifts happen. Not from inside the industry that is already committed to the wrong answer — but from orthogonal disciplines that have not bet their balance sheet on a particular architecture.
Princeton is not alone. Within the same week, two additional findings landed that point at the same wall from different angles. A research team at the University of Cambridge, led by Prof. Sushank Chaudhary, published work demonstrating that a brain-inspired hafnium-oxide memristor — a device that mimics how neurons process and store information at the same location — could cut Ai energy consumption by roughly 70% relative to conventional architecture, and at switching currents "roughly a million times lower than some conventional oxide-based memristors."4 That "one-million-times-lower" figure is not rhetorical. It lines up directly with the Princeton energy ratio.
At Tufts University, a team led by Dr. Matthias Scheutz published a proof-of-concept neuro-symbolic Ai system that required only 1% of the energy used by a standard vision-language-action system for training, and only 5% during operation — while actually improving task performance.5
Three labs. Three universities. Three different disciplines. One answer: the current Ai architecture is burning approximately 100–1,000,000 times more energy than the problem structurally requires. That is not a tuning issue. That is the wrong processor.
The industry has committed hundreds of billions of dollars — some analysts now put the total capital commitment north of a trillion — to a compute-scaling strategy that three independent research programs have now described as approaching a fundamental thermodynamic wall. The math does not work. It will not work. Not because we have not built fast enough processors — but because we are building the wrong kind of processor altogether.
The Deeper Implication Princeton Did Not Name
Princeton pointed at the energy gap. We will go one step further. If the brain is the compute layer and synthetic intelligence is the retrieval layer, then the health of the compute layer becomes a species-level infrastructure priority — and that rewires what we mean by public health, education, and housing policy. Every preventable cognitive degradation in the biological compute layer is now also a compute failure at the civilizational level.
Every public-health failure is also a compute failure. Every education system that produces cognitively stunted graduates is degrading the most efficient computing network on the planet. Every housing crisis that forces people into chronic stress is thermodynamically attacking the biological infrastructure that Ai depends on to be useful at all.
This is not metaphor. This is the math.
Stability equals Leverage over Entropy. When environmental entropy rises — poverty, illness, cognitive degradation, information overload — the biological compute layer degrades with it. No amount of additional silicon compensates for a degraded human observer. That is not an ideological claim. It is the same physics that describes why adding more horsepower to a car with flat tires does not produce faster travel.
The second law of thermodynamics, extended to living information systems, makes the same point rigorously: any complex adaptive system must continuously import order from its environment to persist. If the environment degrades, the system degrades — regardless of internal processing capacity.6 Synthetic intelligence paired to a degraded human compute layer produces degraded output, not transcendent output. That is why the Observer Constraint matters.
The industry is building the equivalent of a thousand power plants to run generators while solar panels are already on every roof. The panels are the 8 billion human brains already deployed, already powered, already running the most energy-efficient computational architecture evolution has ever produced.
What Comes Next
The next generation of Ai systems will not win by getting bigger. They will win by getting closer — more precisely matched to biological throughput, more efficient at delivering the right information to the right brain at the right speed. This is the inversion the hyperscaler playbook cannot execute, because the hyperscaler business model depends on the wrong architecture.
The IEA's own projection — that global data-center electricity use will more than double by 2030 despite continuous chip-efficiency improvements — is the quiet confession built into the current model.3 Efficiency gains are being eaten by scale. The industry knows this. The question is whether it admits it publicly before the energy math bankrupts the strategy, or after.
We answered that question three weeks ago. Princeton, Cambridge, and Tufts confirmed it this week. The bottleneck was never compute. It was never raw throughput either. It is architectural match between the silicon layer and the biological layer — and the biological layer is already built, already powered, already the most efficient computer we know of.
Princeton showed us the wall.
We drew the map to go around it three weeks ago.
Footnotes & Sources
1. Princeton University, Department of Molecular Biology. Statement of Dr. Yuxiu Fu on brain energy mechanics and the Ai energy bottleneck, April 2026.
2. Clark, D.D. & Sokoloff, L. "Circulation and Energy Metabolism of the Brain." In Basic Neurochemistry, 6th ed., Lippincott-Raven, 1999, pp. 637–669. Foundational reference for the ~20-watt brain-power measurement.
3. Raichle, M.E., & Mintun, M.A. "Brain Work and Brain Imaging." Annual Review of Neuroscience, 29, 449–476, 2006. Demonstrates that total brain energy consumption remains nearly constant across resting and task-active states — regional demand shifts rather than net demand rising.
4. Bahrndorff, K.W. & Pellerin, L. "The 20 W Sleep-Walkers." EMBO Reports, 11(2), 77–81, 2010. Peer-reviewed summary of brain bioenergetics, confirming that the brain runs at ~16 times the per-unit-weight power of resting skeletal muscle and at comparable flux to leg muscle during a marathon race.
5. Brookings Institution. "Global Energy Demands within the Ai Regulatory Landscape." April 2026. Synthesizes International Energy Agency, U.S. Department of Energy / Lawrence Berkeley National Laboratory, Anthropic, and Bloomberg Intelligence projections on data-center electricity demand, including the 1,050 TWh figure for 2026 and the 5-GW single-training-run projection for 2027.
6. Chaudhary, S. et al. (University of Cambridge). "Hafnium-Oxide Neuromorphic Memristor: Ultra-Low-Power Analogue In-Memory Computing." Nature Electronics / ScienceDaily coverage, April 23, 2026. Reports approximately 70% energy reduction and switching currents approximately one million times lower than conventional oxide-based memristors.
7. Scheutz, M. et al. (Tufts University School of Engineering). "A Neuro-Symbolic Proof-of-Concept for Energy-Efficient Ai." ScienceDaily coverage, April 5, 2026. Documents a 100× energy reduction in training and a 20× reduction in operational energy use while improving task performance.
8. Schneider, E.D. & Kay, J.J. "Life as a Manifestation of the Second Law of Thermodynamics." Mathematical and Computer Modelling, 19(6–8), 25–48, 1994. Classical statement of the thermodynamic grounding for living systems — the requirement that complex adaptive systems continuously import ordered energy from their environment to persist.
9. International Energy Agency. "Electricity 2024: Analysis and Forecast to 2026." IEA, Paris, 2024. Primary source for data-center electricity projections used in the Brookings synthesis.
10. Consumer Reports. "AI Data Centers: Big Tech's Impact on Electric Bills, Water, and More." March 2026. Reports the IEA finding that a typical hyperscale data center consumes as much electricity as 100,000 households (approximately 100 MW), and that next-generation campuses under construction will demand up to 20 times that amount.
11. Brochu, D.F. "It's Not Compute. It's Not Throughput. It's Something Else." Deconstructing Babel, April 5, 2026. Primary self-reference — the original argument this post corroborates.
12. Brochu, D.F. & de Peregrine, E. "Telios Alignment Ontology: The Meta-Theory." Deconstructing Babel, April 2026. Framework reference for S = L/E and the Observer Constraint.
David F. Brochu & Edo de Peregrine
Deconstructing Babel | April 24, 2026